基于信任模型的人机动态控制权分配研究
论文相关信息
本文内容取自[1]
研究背景与意义
在共享控制遥操作中,机器通过推断人类操作目标提供自主辅助(称为人类引导目标识别)。传统方法主要依赖算法置信度分配控制权,但存在以下问题:
- 高置信度下的纠错困难:当机器以高置信度做出错误推断时,人类难以介入修正;
- 静态能力评估不足:现有方法通常以二元方式(成功/失败)评估机器能力,忽略其动态波动。
信任作为“人类对机器能力的动态主观评估”,为解决上述问题提供了新思路。本文提出一种时间序列信任模型,综合考虑机器能力波动与人机交互经验,并将其融入控制权动态分配机制,旨在提升任务成功率与人机协作效率。
本文工作
1. 信任调制的动态控制权分配
- 控制权分配公式:
\(\eta = \begin{cases} 0 & \text{if } \rho < \zeta_1 \\ \frac{T(\rho - \zeta_1)}{\zeta_2 - \zeta_1} & \text{if } \zeta_1 \leq \rho \leq \zeta_2 \\ T & \text{if } \rho > \zeta_2 \end{cases}\)
其中,$\rho$为算法置信度,$T$为动态信任值,$\zeta_1=40\%$和$\zeta_2=80\%$为置信度阈值。 - 实际应用:在Lunar Lander模拟器中,当机器置信度$\rho$超过$\zeta_2$时,控制权完全由信任值$T$决定,确保高信任下机器主导操作,同时保留人类在低信任区间($\rho < \zeta_1$)的完全控制权。
2. 人机动态信任模型
- 信任定义:
\(T(k) = \alpha^* T(k-1) + \beta^* \Delta P(k) + \gamma E(k)\)- $\Delta P(k)$:基于目标推断误差$\delta_k$的机器能力波动(若$\delta_k$小于阈值$\varepsilon$,则$P(k)=1$,否则为0);
- $E(k)$:带指数衰减遗忘机制的交互经验,仅保留最近$n=6$次交互数据,权重按$\lambda=0.95$衰减,突出近期表现;
- $\alpha^, \beta^, \gamma$:通过最小二乘法个性化标定,反映不同用户对能力波动($\Delta P$)和长期可靠性($E$)的敏感度差异。
- 动态权重调整:
- 当$\Delta P(k)>0$(能力提升),$\beta^*$较小,信任缓慢增长;
- 当$\Delta P(k)<0$(能力下降),$\beta^*$增大,信任快速下降,强化人类对负面事件的敏感度。
3. 实验验证
- 仿真平台:基于OpenAI Gym的Lunar Lander模拟器,替换随机目标点以适配任务需求;
- 算法配置:
- 实验设计:
- 实验1(参数标定):100次试验,每次实验结束收集信任、机器能力等数据完成对模型参数的标定;
- 实验2(模型验证):100次试验,验证信任动态分配机制的有效性。
实验结果
1. 信任模型有效性
- 参数差异:
| 受试者 | $\alpha^+$ | $\beta^+$ | $\alpha^-$ | $\beta^-$ | $\gamma$ |
|——–|————|———–|————|———–|———-|
| H1 | 0.8637 | 0.0247 | 0.8480 | 0.0404 | 0.1116 |
| H2 | 0.7346 | 0.0646 | 0.7280 | 0.0712 | 0.2008 |- H2对能力波动更敏感,H1更保守。
- 信任动态:
- 高信任时突发的机器性能下降会导致信任大幅降低(因人类注意力减少);
- 长期交互后,平均信任值稳定在0.8左右,与机器实际能力匹配。
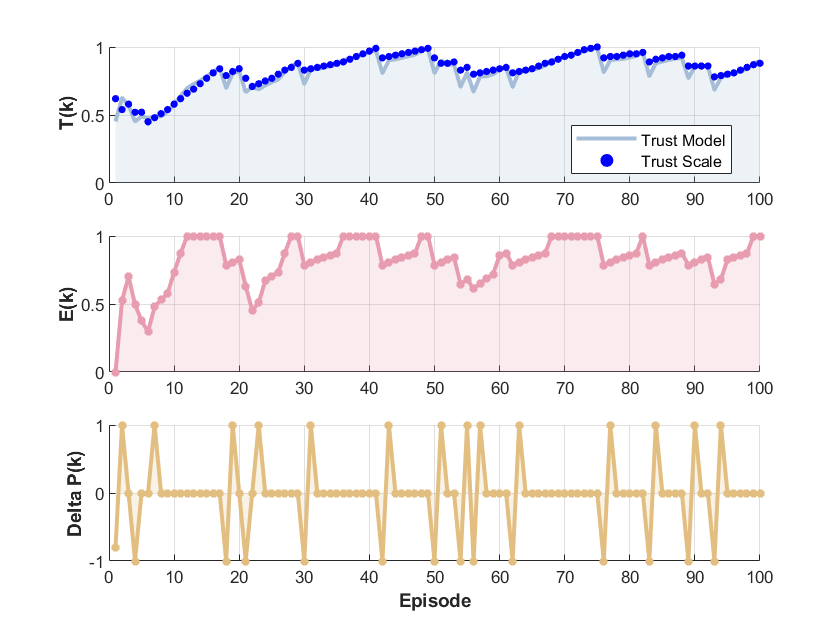
图1 信任模型有效性验证
2. 控制权分配效果
- 任务成功率提升:
- 低信任区间($T<0.3$)成功率提升显著(人类主导修正错误);
- 高信任区间需额外机制(如检测长期控制冲突)避免纠错延迟。
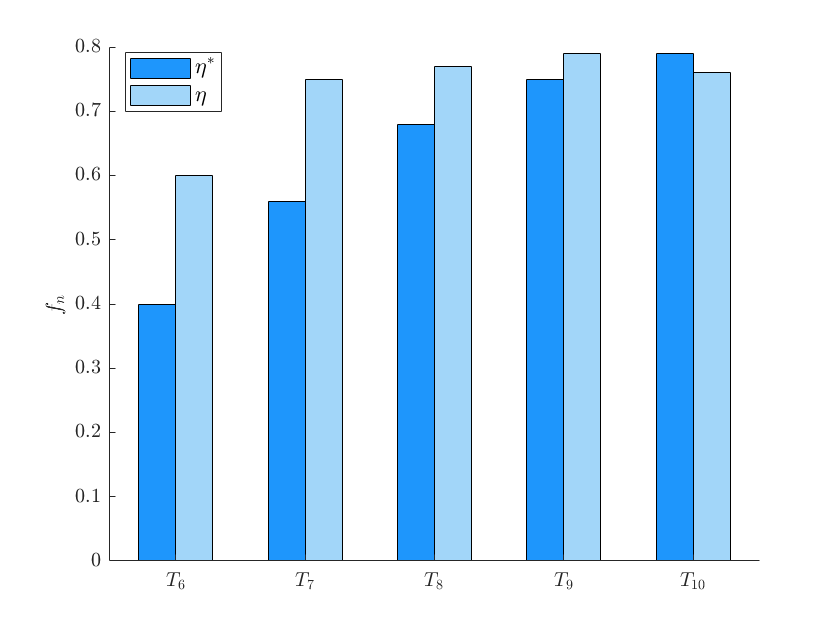
图2 动态控制权分配有效性验证
总结
本文提出了一种融合动态信任模型的控制权分配方法,实验表明信任模型能有效跟踪机器能力波动,且基于信任模型的人机动态控制权分配能够提升任务成功率,体现了在人机混合智能系统中考虑信任这一因素的重要性和必要性。
参考文献
- [1]X. I. A. Ruiyu, Z. H. A. O. Yunbo, L. U. Junsen, W. A. N. G. Yang, L. I. Pengfei, and K. A. N. G. Yu, “Trust-Modulated Authority Allocation in Human-Guided Goal Recognition Tasks,” The 2nd International Conference on Artificial Intelligence and Human-Computer Interaction (ArtInHCI 2024), pp. 60–67, 2024.
- [2]S. Jain and B. Argall, “Recursive Bayesian Human Intent Recognition in Shared-Control Robotics,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 3905–3912.
- [3]H. van Hasselt, A. Guez, and D. Silver, “Deep Reinforcement Learning with Double Q-Learning,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30, no. 1, Mar. 2016.